21 марта 2026, 10:27
День SRE на конференции Teх.Диалог


Все, кто так или иначе занимается сопровождением и обслуживанием высоконагруженных систем сталкиваются с отказами. Просто потому что если взять среднее время наработки на отказ условной виртуалки в 500 дней, то при наличии тысячи виртуальных серверов чисто математически сегодня у вас должны упасть два и это если просто ничего не трогать. А мы трогаем. Релизы, работы, рост данных, внешние факторы (такие как подъем нагрузки и отказы внешних сервисов, телеграм, ты читаешь?) стабильности не добавляют.
Как со всем этим жить, подробно и по шагам расскажем на втором дне конференции Teх.Диалог. Собрали для Вас основные лекции и мастер классы по обеспечению и управлению стабильностью:
Начнем как обычно с мониторинга, просто потому что ехать на машине с заклеенной старыми газетами лобовухой некоторое количество непродуктивно. Поэтому для начала погрузимся в принципы наблюдаемости систем, пройдемся по основным метрикам бизнеса, сервисов и инфры, зацепим трейсы, логи и поиск девиаций в них
Продолжим большим блоком работы с инцидентами и расчетом доступности. Поговорим о том, чем инцидент отличается от алерта, как быстро определить степень влияния и организовать работу на инциденте, экономя драгоценные секунды. Что делать когда починили, как и зачем писать постмортем, когда инцидент считается завершенным и сколько минут писать в черную книжечку прода, если по как-ой причине легли не полностью.
Третий блок посвящен техническим приемам работы с доступностью: чем проектирование сложных высокодоступных систем отличается от проектирования обычных сервисов, нужно ли заморачиваться отказоустойчивостью на этапе MVP, какие методы используются для повышения доступности приложения для пользователя в инфраструктуре и коде и как готовится к подъему нагрузки заранее, что бы не падать в самый ответственный момент.
По результату получился плотный, хорошо дополняющий доклады первого дня мастер-класс с практическими примерами и веселыми историями, особенно для тех, кто в эти истории не попадал. Приходите учиться на чужих ошибках и перенимать опыт, который мы для вас кропотливо собирали многие годы работы с высокими нагрузками на сотнях и тысячах инцидентов.
Билеты по ссылке https://techdialogos.ru/
Увидимся!
Читают сейчас
2 часа назад
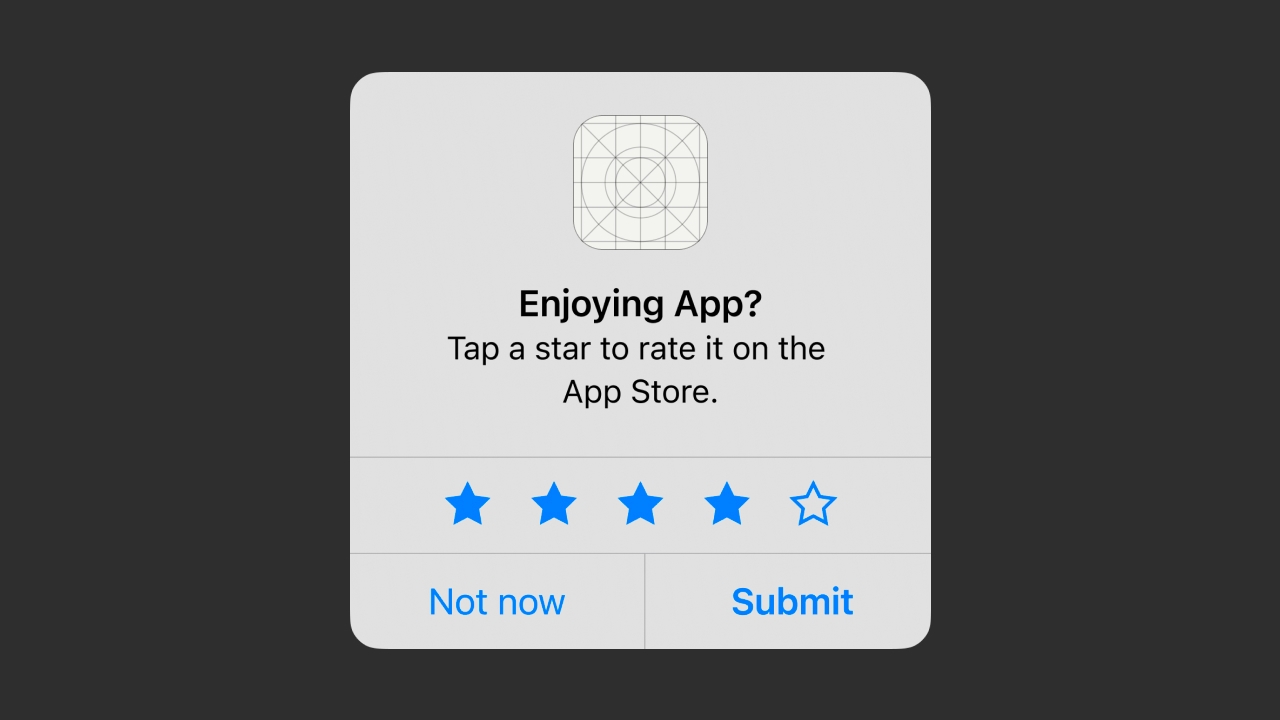
Apple начала отклонять приложения, которые просят пользователя поставить оценку во время онбординга
Исследователи RevenueCat рассказали, что Apple начала отклонять приложения, которые просят пользователей поставить оценку ещё во время онбординга. Разработчики таких приложений начали получать отказы

2 часа назад
Apple исправила дефект в наушниках Beats Studio Buds, который позволял получить доступ к микрофону до сопряжения
Apple выпустила обновление прошивки наушников Beats Studio Buds, которое закрывает уязвимость в работе Bluetooth. Из-за неё злоумышленники рядом с пользователем могли получить доступ к микрофону до со

3 часа назад
Nintendo подтвердила кражу данных в результате кибератаки на дочернюю компанию WebMD
Nintendo of America подтвердила хищение данных в результате кибератаки на дочернюю компанию WebMD — TinyPulse. Сообщается о краже опросов, используемых внутри Nintendo. Системы игровой компании скомпр
3 часа назад
Cnews: «Минпромторг оштрафовал НИИСИ РАН на 110 миллионов рублей за срыв сроков разработки отечественных микросхем»
Министерство промышленности и торговли России оштрафовало Научно-исследовательский институт системных исследований Российской академии наук (НИИСИ РАН), входящий в Курчатовский институт, на 110,4 млн

3 часа назад
Исследователи из сингапурской компании Nipsea разработали сверхчёрное автомобильное покрытие
Учёные из сингапурской компании Nipsea Group разработали сверхчёрное автомобильное покрытие, которое поглощает в среднем 99,9% видимого света. Результаты исследования опубликованы в журнале Matter & L