1 мая 2026, 13:13
Новые TPU восьмого поколения от Google. Обучение и инференс теперь отдельно?


На конференции Google Cloud Next были представлены новые Tensor Processor Unit (TPU) восьмого поколения. В этом поколении чипы анонсированы в двух различных архитектурах TPU — 8t и 8i:
8t (Sunfish) — для обучения,
8i (Zebrafish) — для инференса.
По существу, это дополнительное подтверждение, что решение «один GPU под все задачи» — устаревает. В этом поколении Google глубоко разносит обучение и инференс по разным архитектурам — вплоть до разной топологии сети.
Как следует из поста Амина Вахдата (Amin Vahdat), старшего вице-президента и главного технолога по искусственному интеллекту и инфраструктуре: TPU 8t и TPU 8i были разработаны в сотрудничестве с Google DeepMind для выполнения самых ресурсоемких задач в области искусственного интеллекта и адаптации к масштабируемым архитектурам моделей. TPU восьмого поколения — это результат свыше десятилетней работы (первое поколение было создано в 2015 году).
Как сообщает Вахдат: «Несколько лет назад мы предвидели растущий спрос на логические выводы со стороны клиентов по мере внедрения передовых моделей искусственного интеллекта в производственные процессы. А с появлением AI-агентов мы пришли к выводу, что сообществу будут полезны чипы, индивидуально адаптированные под нужды обучения и обслуживания».
8t для обучения
TPU 8t ориентирован на ресурсоемкие задачи обучения. По заверениям автора: «Благодаря сочетанию максимально возможной вычислительной мощности, общей памяти и пропускной способности межчиповых соединений с максимально возможной энергоэффективностью и продуктивным временем вычислений мы создали систему, которая обеспечивает почти в три раза более высокую вычислительную производительность на компонент по сравнению с предыдущим поколением. Это даёт возможность быстрее внедрять инновации и гарантирует, что наши клиенты будут задавать темп развития отрасли».
В цифрах это выглядит так: векторные, матричные и SparseCore-ядра, дополненные 128 МБ SRAM и 216 ГБ HBM3e. Для вертикального масштабирования используется межчиповый интерконнект ICI со скоростью 19,2 Тбит/с, для горизонтального — 400 Гбит/с. Это даёт возможность самым большим моделям применять единый огромный пул памяти.

Кроме того, TPU 8t получили расширенные возможности RAS (Remote Access Service). Телеметрия в реальном времени, автоматическое обнаружение неисправных каналов ICI и перенаправление трафика без прерывания задания, а также оптическая коммутация каналов (OCS), которая перенастраивает оборудование в случае сбоев без участия человека… Все это даёт возможность довести уровень утилизации чипа до 97%.
Superpod состоит из 9 600 чипов с 2 ПБ общей памяти: 121 экзафлопс вычислений. А новая сеть Virgo, которая использует плоскую двухуровневую неблокирующую топологию, через JAX и Pathways даёт возможность объединить до миллиона TPU в контексте нескольких ЦОД.

Дополнительно были представлены TPUDirect RDMA и TPUDirect Storage.
TPUDirect RDMA — это прямая передача данных между памятью TPU (HBM) и сетевыми картами (NIC).
TPUDirect Storage — прямой доступ к памяти между TPU и высокоскоростным управляемым хранилищем, таким как 10T Lustre.


Арендуйте GPU за 1 рубль!
Выберите нужную конфигурацию в панели управления Selectel. *
Подробнее →
8i для инференса
TPU 8i, в свою очередь, ориентирован на инференс. Чип разработан для обработки сложной совместной итеративной работы множества специализированных агентов, часто объединяющихся в сложные потоки для предоставления решений и аналитических данных по самым сложным задачам, — говорит Вахдат.
TPU 8i получил 288 ГБ памяти HBM3e в паре с 384 МБ SRAM — такой объем SRAM помогает удерживать активные веса модели на самом чипе. А новый алгоритм ускорения коллективных операций (Collectives Acceleration Engine, CAE), по информации Google, разгружает глобальные операции, сокращая внутреннюю задержку в пять раз

Как и у 8t, пропускная способность межчиповых взаимодействий удвоена до 19,2 Тбит/с. Тем не менее сетевая топология отличается — в данном случае это Boardfly.
В основе лежит Building Block (BB), в котором четыре чипа объединены в кольцо с полной связностью. BB масштабируются в группу из восьми штук. 36 групп замыкаются через оптические коммутаторы в под. Сетевой диаметр сокращен до семи хопов, поскольку для MoE-инференса важно меньшее количество сетевых переходов между чипами.

TPU 8i масштабируется в Superpod до 1 152 чипов в одном кластере с производительностью 11,6 экзафлопс. По заявлению Google, TPU 8i на 80% выгоднее по соотношению производительности и цены, чем Ironwood — за те же деньги можно обслужить почти вдвое больше пользователей.
Итоги
Оба чипа в первый раз работают на собственных ARM-процессорах Axion в качестве хост-CPU и поддерживают СЖО
Удобная таблица для сравнения спецификаций:

Как говорит Google: «Оба чипа поступят в продажу в конце этого года и могут быть использованы в составе гиперкомпьютера Google с искусственным интеллектом, который объединяет специализированное оборудование (вычислительные ресурсы, системы хранения данных, сетевые ресурсы), открытое программное обеспечение (фреймворки, механизмы логического вывода) и гибкие модели потребления (оркестрация, управление кластерами и модели доставки) в единый стек».
Коммерческий контекст этого анонса очевиден. Google некоторое количество раз в пресс-релизе указывает на возросшую продуктивность и очевидную экономию, связанную с этим. В дополнение к этого, теперь это не просто альтернатива GPU, а усиленный сдвиг на отдельный ускоритель для разных AI-задач. Еще одна из увлекательных новостей: TPU 8t масштабируется до миллиона чипов в одном кластере — это больше, чем публично известные размеры кластеров других компании.
Что думаете насчет новых TPU? Делитесь мнением в комментариях.
Читают сейчас

8 часов назад
Руководящий комитет GNU Compiler Collection принял политику в отношении ИИ
Руководящий комитет GCC официально принял политику, регулирующую использование искусственного интеллекта и больших языковых моделей в GNU Compiler Collection. Теперь проект будет отклонять любые матер

8 часов назад
Американские инженеры представили прототип умного кольца, которое отслеживает химический состав пота
Инженеры Калифорнийского университета в Сан‑Диего создали прототип умного кольца, которое анализирует состав пота с пальцев для отслеживания биомаркеров. Разработка демонстрирует потенциал будущих сма

8 часов назад
Марк Цукерберг: через пять лет у миллиардов людей будут собственные ИИ‑агенты
Основатель и генеральный директор Meta* Марк Цукерберг заявил инвесторам, что через пять лет у миллиардов людей будут собственные персональные ИИ‑агенты. По его словам, эти агенты будут работать кругл
8 часов назад
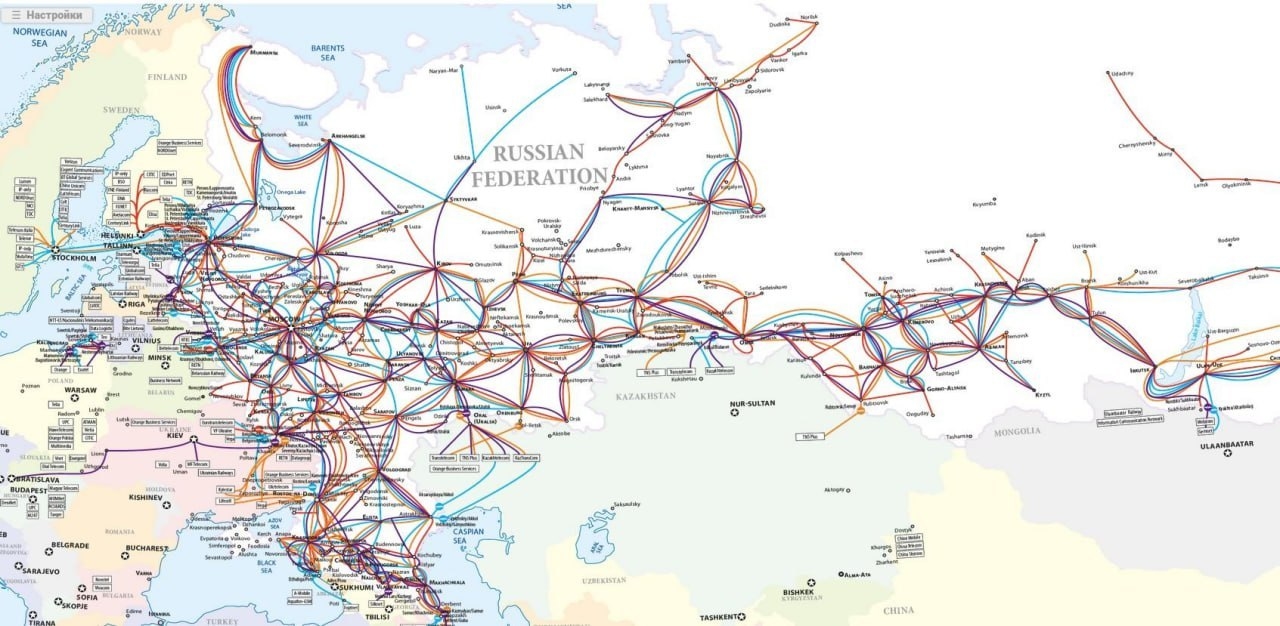
Финляндия отключит от России часть международного интернет-трафика
Финляндия ОТКЛЮЧИТ от России часть международного интернет-трафика — с 2027 года страна перестанет обслуживать опоры ЛЭП, по которым проходит часть международных линий связи с Россией. После прекращен
9 часов назад
Microsoft раскрыла сроки прекращения поддержки Whiteboard
Ранее приложение Microsoft Whiteboard для Windows 11 начало отображать всплывающее окно, указывающее на прекращение поддержки. Теперь Microsoft поделилась некоторыми подробностями по теме. Ознакомитьс