28 мая 2026, 20:10
Cerebras ускорила 1 трлн схема kimi K2.6 до тысяча т/sec
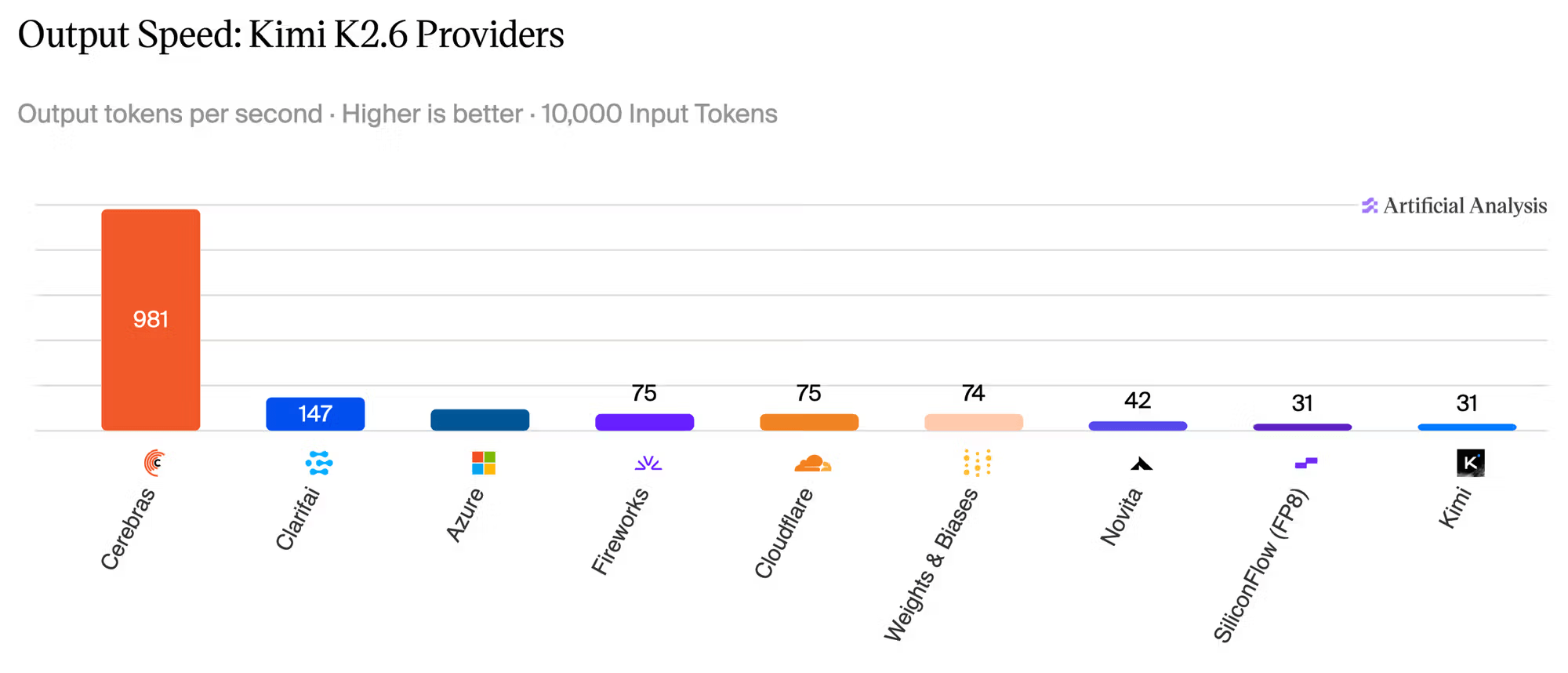
Недавно компания производитель чипов Cerebras добавила топовую открытую трилионную модель Kimi k2.6, на свою платформу.
В сравнении со другими компаниями - это невероятный апгрейд скорости. По сути теперь доступна флагманская скорость для флагманской нейросетевой модели.
К сожалению сейчас доступна только enterprise клиентам. Для остальных же доступна тоже интересная схема glm-4.7.
Давайте разберемся, что происходит с Kimi K2.6. Эта схема сейчас — настоящий король open-weight для кодинга и агентов.
Она просто разрывает бенчмарки: на SWE-Bench Pro выбила 58.6%, обойдя Claude Opus 4.6 и встав вровень с GPT-5.4. А на тестах для агентов (типа Humanity's Last Exam или DeepSearchQA) — вообще лидер.
Авторы уже вовсю юзают её как бесплатную альтернативу закрытым топам. Особенно для кода: K2.6 прям чувствует, как делать чистый клиентская часть, и стала топовой для генерации full-stack приложений. В версии 2.6 она пошла дальше — теперь это полноценный full-stack воркфлоу: аутентификация, базы данных, длинные цепочки действий агентов.
Как это вообще работает на Cerebras
У Cerebras есть свой движок (Wafer-Scale Engine), который заточен под масштаб. Кластер CS-3 можно настроить так, что он будет тащить модели с триллионами параметров — и для обучения, и для инференса. Они вылизали софт до блеска, чтобы обслуживать ее.
Хитрость в том, как они хранят модель: Kimi K2.6 лежит в оригинальных 4-битных весах, но все вычисления идут в 16-битной плавающей точкой. Так и точность сохраняется, и памяти меньше жрёт. Веса размазаны по нескольким чипам, а активации стримятся между ними. Связь между слоями идёт прямо по сети на движке — у него пропускная способность в 200+ раз выше, чем у NVLink на NVL72. Плюс кастомные ядра и спекулятивный декодинг — в итоге MoE-модель на триллион параметров выдаёт почти 1000 токенов в секунду. Мировой рекорд.
Что это даёт
Агентный кодинг — сейчас самая жирная тема для LLM, и он дико чувствителен к скорости инференса. На 1к токенов в секунду Kimi генерирует код на порядок быстрее, чем Claude Opus. Разработчики могут работать моментально, быстрее добираться до финального решения и не распыляться.
Фронтенд-итерации — практически мгновенные. Рефакторинг кода и сложные баги — в разы быстрее. Всё, что раньше отнимало кучу времени, теперь делается за долю секунд
Читают сейчас

1 час назад
Microsoft добавит в Outlook функцию для более продвинутых автоответов
Согласно последней записи в дорожной карте Microsoft 365 для Outlook, компания добавляет в Outlook для Windows новую функцию автоматического ответа на основе правил. Этот новый механизм должен позволи

3 часа назад
Anthropic продлили доступ к Claude Fable 5 на неделю
Anthropic продлили доступ к своему флагману – Claude Fable 5 на еще одну неделю, до 19 июля. Равным образом продлили увеличение недельных лимитов на 50% на ближайшие семь дней. Читать далее

4 часа назад
Платформа распознавания лиц в магазинах Великобритании вскоре будет мгновенно оповещать полицию о появлении рецидивистов
Техника распознавания лиц в магазинах Великобритании вскоре позволит мгновенно оповещать полицию о присутствии лиц, которые неоднократно совершали преступления, пишет Guardian. Сообщается о системе Fa
9 часов назад
OpenAI и Google продают ИИ-модели китайским компаниям из чёрного списка США
Американские ИИ-гиганты продолжают функционировать с китайскими технологическими корпорациями, вопреки санкционные ограничения. Как выяснила Financial Times, OpenAI и Google предоставляют услуги в обл

11 часов назад
Суды Китая: игровые аккаунты, внутриигровые предметы и цифровые покупки можно передавать по наследству
Несколько семей в Китае добились через суд права наследования игровых аккаунтов, внутриигровых предметов и цифровых покупок после смерти их владельцев. Пользователь Reddit рассказал о нескольких решен