8 апреля 2026, 10:59
VoxCPM2: открытая 2B TTS-модель на 30 языках

VoxCPM2 - крупное обновление открытой системы синтеза речи VoxCPM. Модель обучена на более 2 млн. часов мультиязычных аудиоданных и поддерживает 30 языков, в том числе русский, китайский, английский, японский, корейский, арабский и хинди (плюс 9 диалектов китайского).
За проектом стоит OpenBMB, структура при Университете Цинхуа, объединяющая академическую лабораторию THUNLP и коммерческую компанию ModelBest.
THUNLP - одна из сильнейших академических групп по LLM в Азии, которой руководит легенда китайского NLP, профессор Maosong Sun.
OpenBMB известна сериями CPM, MiniCPM, AgentCPM и фреймворками BMTrain и OpenPrompt.
В отличие современных TTS-систем, VoxCPM2 работает напрямую с непрерывными представлениями в латентном пространстве AudioVAE V2.
Пайплайн состоит из 4 стадий: LocEnc, TSLM, RALM и LocDiT. На выходе - аудио с частотой 48 кГц студийного качества: асимметричная архитектура AudioVAE V2 принимает референс на 16 кГц и повышает разрешение без внешнего апсемплера.
Обновление добавило 2 новые возможности
Voice Design создает голос по текстовому описанию: достаточно указать пол, возраст, тембр, эмоцию и темп - никакого референсного аудио не нужно.
Controllable Voice Cloning клонирует голос по короткому аудиофрагменту и в довесок даёт возможность управлять стилем, эмоциями и скоростью речи, сохраняя оригинальный тембр.
Из версии 1.5 перешел режим Ultimate Cloning: если передать вместе с референсом его точный транскрипт, схема воспроизводит ритм, интонации и манеру речи.
Тесты
На Seed-TTS-eval схема демонстрирует WER 1.84% на английском и CER 0.97% на китайском при сходстве голоса (SIM) 75.3% и 79.5% соответственно.
На мультиязычном Minimax-MLS-test платформа лидирует по SIM в подавляющем большинстве из 24 языков, опережая Minimax, ElevenLabs, FishAudio S2 и Qwen3-TTS.
В задаче генерации голоса по описанию схема набирает лучшие баллы среди open-source решений на InstructTTSEval в английском языке.
Модель потребляет приблизительно 8 ГБ VRAM
Скорость инференса по соотношению времени, затраченного моделью на генерацию аудио к длительности самого аудио - приблизительно 0.3 на NVIDIA RTX 4090. На движке Nano-vLLM этот метрика снижается до 0.13 (подходит для стриминга в реальном времени).
Есть скрипты и гайд для SFT (добавления нового языка или домена) или LoRA для глубокой имитации конкретного спикера. LoRA потребует 5-10 минут аудио и 20 ГБ VRAM.
Пример генерации аудио на демо-спейсе HF без клонирования и постобработке - в видеофайле поста.
Лицензирование: Apache 2.0 License.
Читают сейчас

26 минут назад
JetBrains протестировали скилл Caveman: обещанные 65% экономии токенов превратились в 8.5%
Caveman — скилл для агентов вроде Claude Code, который переводит текстовые ответы в рубленый «пещерный» стиль без служебных слов. Код и вызовы инструментов не трогает. Целых 85 тысяч звёзд на GitHub.

40 минут назад
DeepSeek тайно собирает команду для собственного чипа — вслед за OpenAI и Anthropic
DeepSeek, год назад взорвавший рынок своей R1-моделью, начал разработку собственного чипа для инференса. Проект запущен приблизительно года назад, но только сейчас стал достоянием общественности. Проц
44 минуты назад
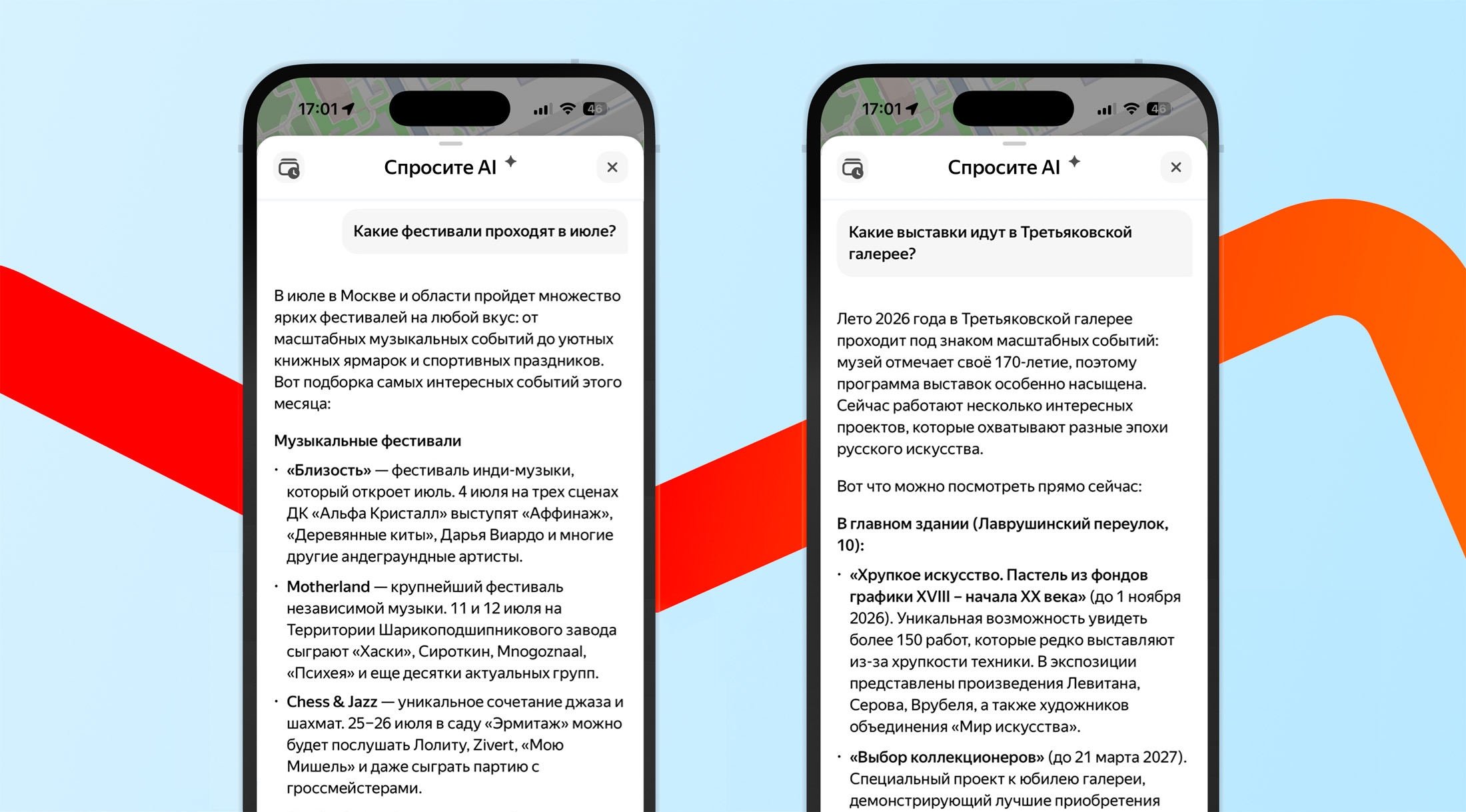
ИИ-чат в «Яндекс Картах» научили помогать пользователям находить подходящие места для культурного и активного отдыха
В служба «Яндекс Карты» разработчики добавили возможность для пользователей в ИИ-чате находить подходящие места для культурного и активного отдыха. Ознакомиться далее

46 минут назад
Google планирует увеличить минимальный объём встроенной памяти и повысить стоимость смартфонов серии Pixel 11
Google повысит цены на грядущую серию смартфонов Pixel 11, а равным образом откажется от варианта со 128 ГБ постоянной памяти, сообщил инсайдер billbil-kun с сайта Dealabs. Релиз линейки должен состоя

59 минут назад
GPT-5.6 выйдет в четверг
OpenAI объявила, что GPT-5.6 Sol вместе с Terra и Luna станут публично доступны в этот четверг, 9 июля, а превью доступ для бизнеса организация расширяет на весь мир уже сейчас. Так заканчивается почт