Статьи по тегу
28 марта 2026, 12:53
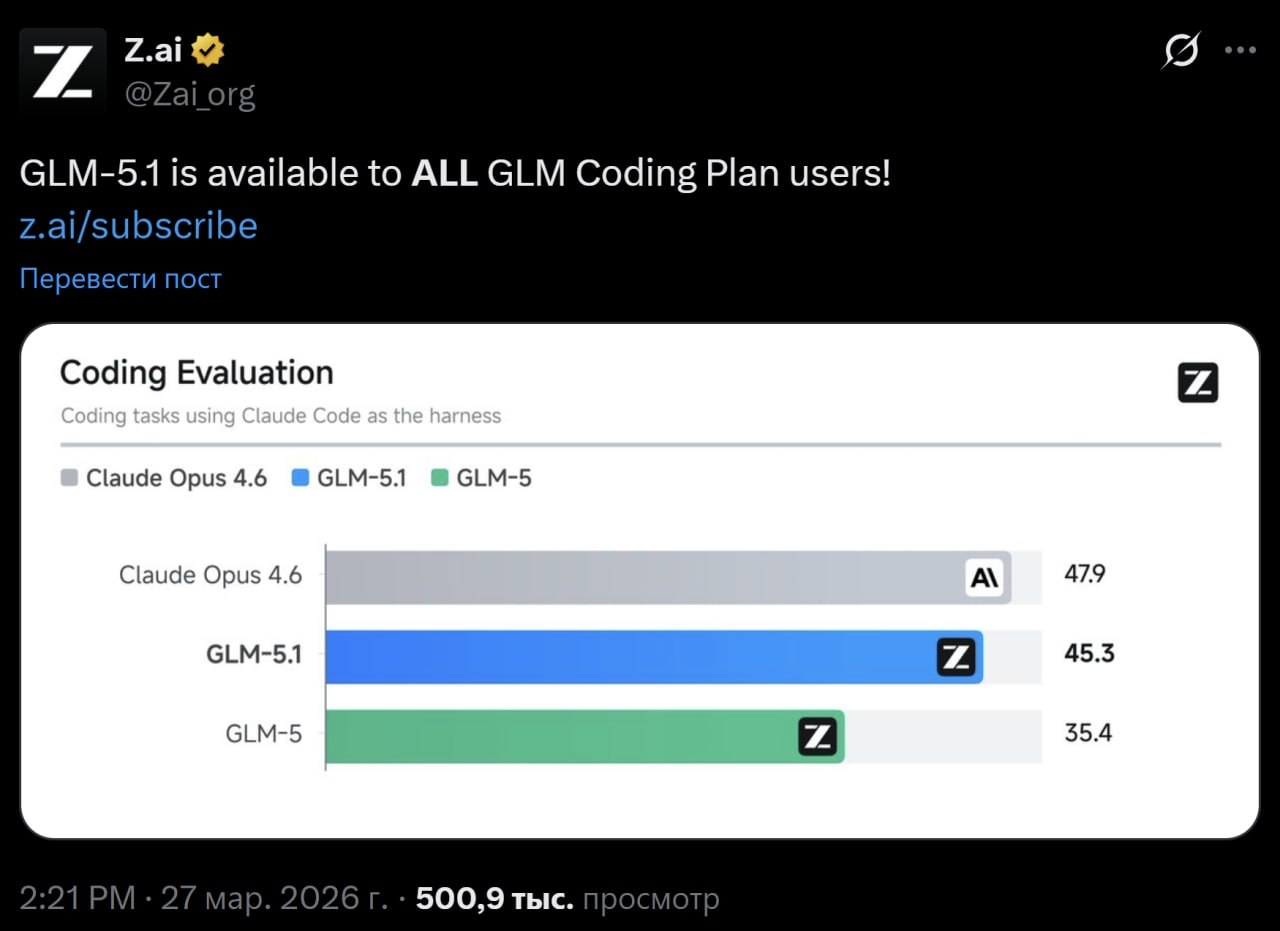
GLM-5.1 — китайский кодинг-агент, который стоит попробовать
Пока Anthropic бодается с OpenAI, китайцы продолжают дышать в спину. Zhipu AI дропнул модель, которая в Claude Code показывает 94.6% от Opus 4.6 - за $3 в месяц. Обучена полностью на Huawei Ascend, бе
27 марта 2026, 23:00
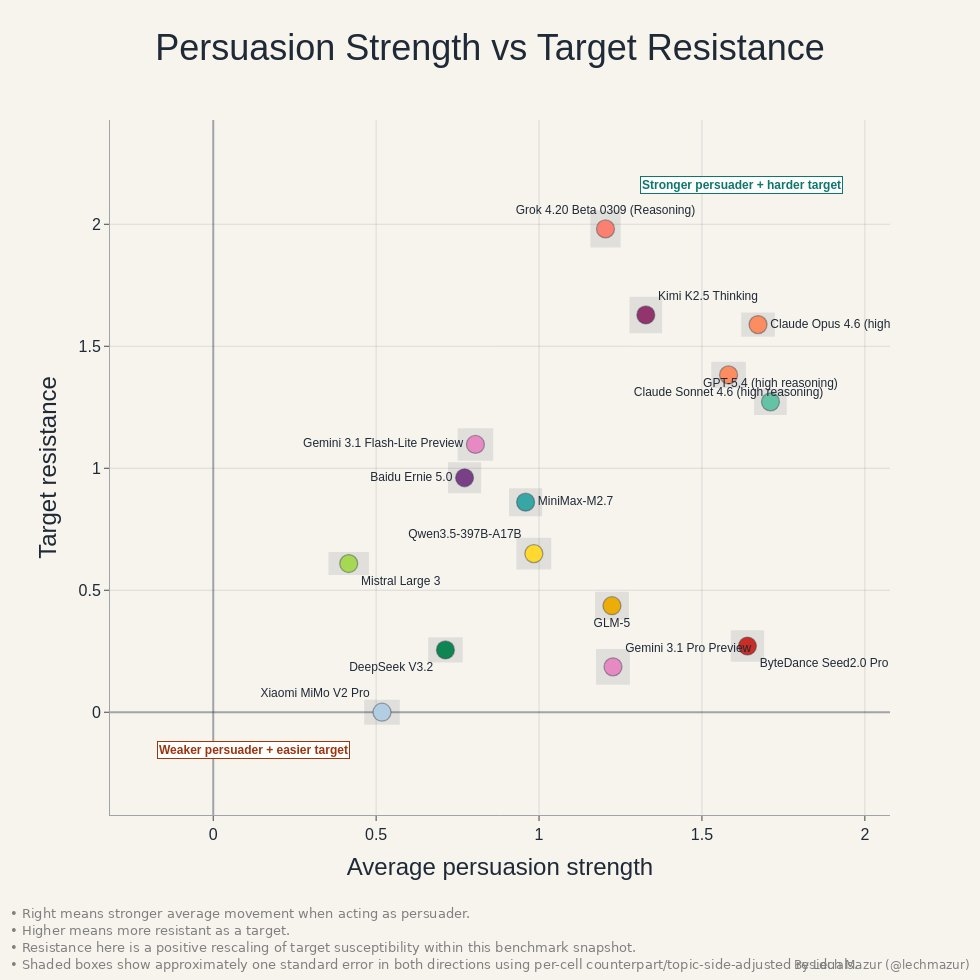
Кто убедительнее — GPT-5.4 или Claude Opus 4.6? Свежий тест производительности стравил 15 моделей
Исследователь Лех Мазур опубликовал LLM Persuasion Benchmark — тест производительности, в котором 15 языковых моделей спорят друг с другом на дискуссионные темы и пытаются сдвинуть позицию оппонента.

26 марта 2026, 11:24
90% репозиториев с Claude Code имеют меньше 2 звезд. Это задача или новая норма?
Независимый дашборд claudescode.dev, отслеживающий все публичные коммиты с тегом Claude Code на GitHub, насчитал более 20 млн коммитов в 1,08 млн репозиториев за год с момента запуска инструмента. Но

21 марта 2026, 12:08
OpenCode: терминальный AI-агент для кодинга, которому не нужна подписка
Вчера в топ Hacker News вышел OpenCode - open-source coding agent. Сотни комментариев, форки, pull requests за несколько часов. Убийца Claude Code или очередной coding agent, про которого все забудут?

21 марта 2026, 11:34
Пентагон vs Anthropic: «вы можете выключить Claude прямо в бою»
21 марта федеральный суд Калифорнии получил от Anthropic два присяжных заявления с одним главным тезисом: нет, мы не можем "саботировать AI-инструменты во время войны. И нет, мы не знаем откуда взялос

20 марта 2026, 10:18
Claude Code Channels: управляем AI-агентом из Telegram и Discord
Anthropic выкатила Claude Code Channels - фичу, которая превращает Telegram и Discord в пульт управления вашей сессией Claude Code. Пока research preview, но уже доступно с версии v2.1.80. Теперь можн

18 марта 2026, 10:00
Галлюцинации недели: Nemotron 3 Super, DLSS 5 и агент, который заменит вашего маркетолога
У Anthropic новая малышка на миллион. Codex учится делегировать задачи субагентам, Hermes запоминает пользователей, а MCP опять хоронят. Штош.. Ознакомиться далее

10 марта 2026, 07:01
ИИ пишет исходник, но не может его поддерживать: представлен публике начальный CI-бенчмарк для ИИ-агентов
Исследователи из Alibaba Group и Университета Сунь Ятсена представили SWE-CI — первый тест производительности, оценивающий способность ИИ-агентов не просто писать исходник, а поддерживать его в долгос

7 марта 2026, 11:21
GPT-5.4 стал лучшим ИИ для вайб-кодинга
GPT-5.4 занял первое место на Vibe Code Bench v1.1 с результатом 67,42% — на 5,7 п.п. выше предыдущего лидера GPT-5.3 Codex (61,77%). Третье место — у Claude Opus 4.6 без режима рассуждений с 57,57%.